Todo lo que se sabe de las NVIDIA RTX 50

Si bien todavía es pronto para hablar acerca de los rumores de las NVIDIA RTX 50, creednos que vais a ver una enorme cantidad de ellos y diferentes especificaciones en los próximos dos años. Es por ello que hemos decidido reunirlos todos aquí para irlos comentando con el tiempo y no tengáis que buscarlos desperdigados alrededor de varios artículos distintos. A medida que nos acerquemos a la fecha de lanzamiento iremos marcando información y marcando como verdadera o falsa la que haya aparecido con el paso del tiempo.
Índice de contenidos
Índice de contenidos
¿Qué son las NVIDIA RTX 50?

Bajo este nombre conocemos al conjunto de tarjetas gráficas con GPU NVIDIA Blackwell para PC, el cual no es el mismo que el que veremos en servidores, GB100, y se basará en los chips GB20x, empezando por el GB202 que será el tope de gama y reemplazará al actual AD102 de las RTX 4090.
Su fecha de lanzamiento se espera para 2025, por lo que todavía faltan dos largos años. Si tenemos en cuenta que el proceso de fabricación previa y de lanzamiento de un chip suele un año en ejecutarse, está claro que este se encuentra todavía en la mesa de diseño. Por lo que hablar de especificaciones definitivas es cuando menos arriesgado.
Sin embargo, uno de los temas que más suenan es el posible uso del nodo de Intel 18A, equivalente al nodo N2 de TSMC para estas tarjetas gráficas. Claro está, que hemos de tener en cuenta de que se trata de algo no confirmado, pero de ser así no solo las NVIDIA RTX 50 abandonarían a la fundición taiwanesa, sino que darían un salto de dos litografías completas al no usar los nodos de 3 nm.
Posibles especificaciones técnicas

Recordad que estas no son oficiales de NVIDIA, por lo que van a sufrir cambios, pero a fecha de septiembre de 2023 la única supuesta fuente fiable que tenemos es un mensaje en un foro, cuya captura de pantalla de puede ver arriba. Y a partir de la cual se han ido construyendo los diferentes rumores que han ido apareciendo en la red. De forma resumida, lo que dice es lo siguiente:
- Aumento del 50% en escala (presumiblemente núcleos).
- Aumento del 52% en ancho de banda de memoria.
- Aumento del 78% en caché (presumiblemente caché L2).
- Aumento del 15% en frecuencia (presumiblemente GPU boost).
- Una mejora de 1.7 veces (presumiblemente rendimiento).
Posible configuración

En vez de hacer copipega de otros lugares, lo que haré será desglosar por completo la ecuación tomando como referencia a la RTX 4090 actual. Para ello me basaré en los dos puntos: su potencia de cálculo actual máxima en FP32 y la velocidad de reloj máxima actual, siendo esta una de las variables a partir de la cual se obtiene dicha cifra.
(128 núcleos (SM)*128 unidades FP32 por núcleo)*2 (operaciones FMA)*2520 MHz (Boost Clock) = 82.58 TFLOPS
En cambio, respecto a la más potente de las NVIDIA RTX 50, la RTX 5090, de ser ciertos rumores tendríamos:
(x núcleos (SM)*128 unidades FP32 por núcleo)*2 (operaciones FMA)*2898 MHz (Boost Clock) = 140.39 TFLOPS
Por lo que la clave aquí es despejar la incógnita y conocer la cantidad de núcleos SM dentro de la hipotética RTX 50.
(140.39*10^12)/(128*2)*(2898*10^6) =189.23 núcleos SM.
La cifra no es exacta, pero la vamos a redondear a 192 núcleos CUDA, el motivo de ellos es que según los rumores filtrados por Kopite7Kimi, la RTX 5090 de las NVIDIA RTX 50 tendrá un bus de 512 bits. Si el chip AD102 tiene 144 núcleos SM para un bus de 384 bits, entonces la cifra de 192 unidades para el GB202 de 512 bits tiene sentido. Por lo que al final la cosa quedaría en 8 GPC con 24 SM por GPC, para llegar a los 192 núcleos SM. Lo que explicaría el aumento en un 33% del área, pero no del 50%, aunque esto se explicaría con mejoras arquitecturales.
¿GDDR7 o GDDR6X?

Otro tema importante es que vamos a ver, supuestamente, un aumento en el ancho de banda del 52%, esto son 1.5 TB/s aproximadamente, a esto hay que añadirle el rumor fiable de un bus de 512 bits. El cual por sí solo y sin cambiar el tipo de memoria, GDDR6X a 21 Gbps, debería aumentar el ancho de banda a los 1.344 TB/s. Si NVIDIA termina usando la GDDR6X a 24 Gbps que puede alcanzar sin problemas dicha memoria en la actualidad, entonces llegamos a la cifra de ancho de banda sin problemas, por lo que deja de ser necesaria la GDDR7 y sus 36 Gbps.
Claro está, que una GPU para 2025 haciendo empleo de la GDDR6X, en vez de la nueva GDDR7 suena chocante. en todo caso es posible que NVIDIA tenga una versión con dicha memoria esperando a graduarla a la siguiente generación cuando llegue el momento. ¿El problema? La correlación directa entre controladores de memoria y particiones de caché.
Es por ello que quien escribe esto, es muy escéptico sobre la información que supuestamente se ha filtrado o más bien de la interpretación que están dando los medios respecto a las NVIDIA RTX 50, ya que están suponiendo una Ada Lovelace vitaminada y no un cambio en la organización más profundo. Aunque sobre ello ya hablaremos en una actualización posterior de este mismo artículo.
Herencias de las H100 en las NVIDIA RTX 50, inéditas en las RTX 40

Una de la particularidades del chip H100 es que si miramos la versión de CUDA que soporta, veremos que es la sm_90 (CUDA 12), en cambio, si hablamos de los AD10x la versión es la sm_89 (CUDA 11.8), por lo que sigue en la versión anterior, aunque es la mas avanzada. Por lo que hay elementos de las H100 que veremos en los chips GB100 y GB20x, estos últimos lo de las NVIDIA RTX 50.
En cuanto a organización interna, las H100 de NVIDIA no son iguales a las AD10x utilizadas en las RTX 4000/RTX 40, pero las RTX 50 pueden heredar parte de dichos cambios.
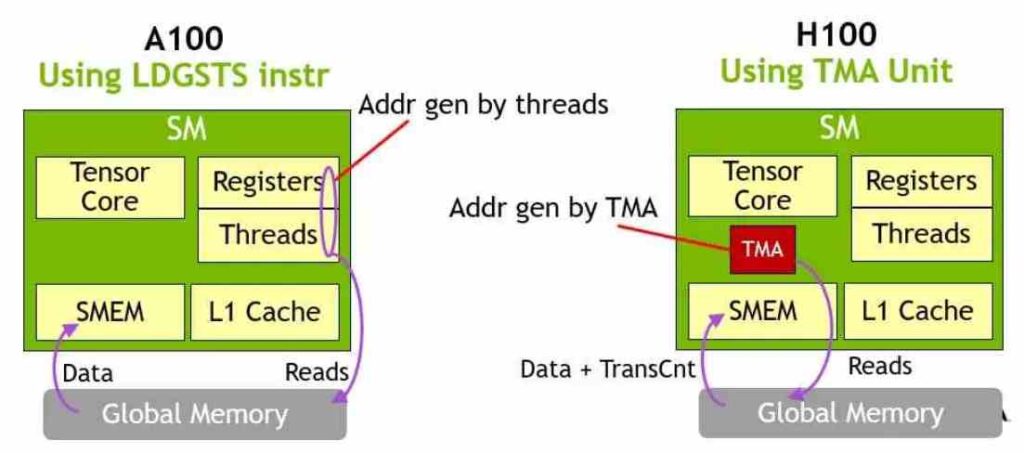
- Cada uno de los núcleos de las H100 tienen una unidad llamada Tensor Memory Accelerator la cual puede transmitir largos bloques de memoria entre la memoria global dentro de la GPU, no confundir con la L2, y la memoria local compartida de los SM.
- No olvidemos que la memoria local por SM y la caché es la misma, pero configurando una parte como caché y la otra como memoria local compartida.
- La memoria local compartida no es caché es un pozo de RAM interno alternativo con el que los núcleos de la GPU pueden realizar operaciones muy rápidas a muy baja latencia.
- La unidad sirve para liberar a las unidades SIMD de tener que generar ellas las diferentes direcciones de memoria interna para la transferencia continua de bloques de información.
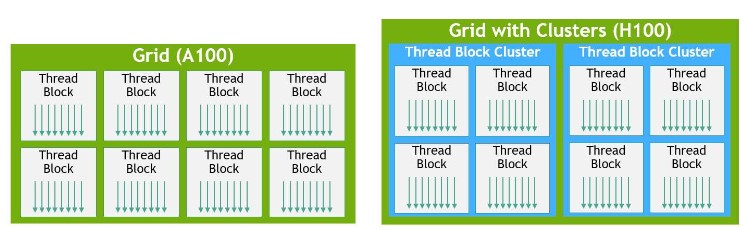
El otro punto que heredará son los Thread Block Clusters, con ello se refieren a que a partir de CUDA 12, los SM en las GPU de NVIDIA comparten en bloques de 4 núcleos o 4 SM tanto la memoria local compartida como la caché de primer nivel. ¿La ventaja principal de esto? Evita tener que copiar a la memoria global para sincronizar datos.
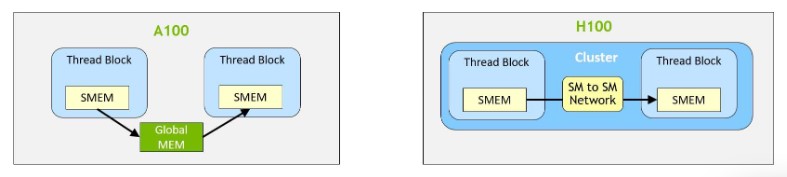
Todo esto son cambios arquitecturales seguros que veremos en las NVIDIA RTX 50, ya que son parte esencial de CUDA 12 en adelante.
Esta entrada está en proceso de desarrollo, cada cierto tiempo irá recibiendo actualizaciones. Por lo que visitadla de tanto en cuando para ver cambios y actualizaciones a la misma.



[…] En todo caso, cabe aclarar que no nos referimos al chip que veremos en las próximas GeForce, el cual es el GB202, sino al sucesor del actual H100, la cual además, por motivos de demanda se habría adelantado al […]
[…] a que el rumor no lo dice, las especificaciones podrían haber ido a la baja, y pasar de los 192 SM a los 144 SM, es decir, la misma configuración que tenía que tener la cancelada RTX 4090 Ti. Sin […]