NVIDIA usará chiplets en su GPU Next Gen: Blackwell

Blackwell es el nombre en clave para la próxima generación de GPU de NVIDIA, tanto para el mercado de computación de alto rendimiento o HPC, como para el mercado de PC. En el primer caso, reemplazará a los actuales chips H100, mientras que en el segundo, a los chips AD10X bajo arquitectura Lovelace de las actuales RTX 40. En realidad estamos hablando de dos futuras arquitecturas bajo un nombre en común. Pues bien, todo apunta a que NVIDIA Blackwell usará chiplets
Índice de contenidos
Tabla de contenidos
NVIDIA Blackwell se basará en chiplets
La fuente de todo ello es el siempre fiable Kopite7Kimi donde comenta que Blackwell usará chiplets. Por lo que NVIDIA tomará el mismo camino que ya ha tomado AMD con las Instinct MI200 primero y las MI300 después. Aunque por el momento desconocemos detalles arquitecturales, lo que sí que está muy claro es que a no ser que haya un giro de timón de última ahora, al menos en lo que es el mercado HPC, los de Jensen Huang debería seguir con TSMC.
El uso de chiplets en Blackwell no solo supone tener el chip separado en varios, sino que no todas las partes tengan que usar las litografías más avanzadas, ya que realmente no sacan provecho de usarlas en cuanto a rendimiento. Si no más bien que NVIDIA consigue con ello romper el límite de la retícula, que de hacerse en una sola pieza no puede superar los 858 mm² de tamaño.
Ahora bien, desde cierto punto de vista es falso decir que NVIDIA vaya a utilizar por primera vez una configuración por chiplets, sin embargo, dicha afirmación tiene trampa. Y es que los chips disgregados o en chiplets requieren de un interposer o base die para la intercomunicación, lo mismo que ocurre que cuando se utiliza la memoria HBM. Hemos de partir del hecho que TSMC no solo fabrica los chips, sino que es la encargada de diseñar lo que son dichos interposers o base chips para que NVIDIA y AMD coloquen las diferentes piezas y se intercomuniquen entre sí.
Un diseño muy parecido al del MI300 de AMD
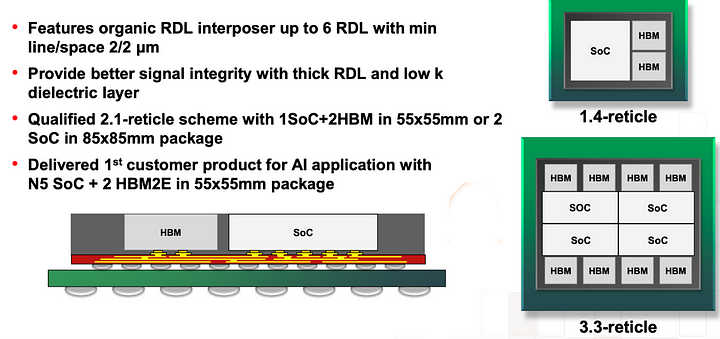
La tecnología de Interposer de TSMC recibe el nombre de CoWoS y hemos visto su versión más avanzada recientemente con las MI300 de AMD que se lanzarán en unos meses, sin embargo, es interesante ver las especificaciones de la propia fundición de chips asiática para entender que vamos a ver en el Blackwell por chiplets o GB100.
Desde el momento en que es necesaria la memoria HBM y esta se ha hecho imprescindible, estaríamos hablando de 4 base die o interposers, cada uno con un tamaño de 55 x 55 mm, en los que van montadas dos pilas de dicha memoria también colocadas encima del mismo y el propio chiplet de la GPU. Recordemos que la configuración actual en el caso de NVIDIA, H100, es de 6 pilas de memoria HBM. Sin embargo, lo importante aquí es que permite sacar diseños que requerirían una imposible retícula 3.3 veces mayor en el caso de poderse construir de forma monolítica.
Recordemos que en el caso del MI300, elementos como el procesador de comandos y la caché de último nivel se encuentran integrados en el interposer. Desconocemos cuál será la opción escogida por NVIDIA y al final y los detalles únicos sobre su diseño, solo que Blackwell en chiplets se verá definido por la tecnología CoWoS de TSMC.
Cambios importantes en estructura, ¿pero no en número de núcleos?
La mayor amenaza sobre NVIDIA es el hecho que AMD haya conseguido, con el MI300, tener un diseño que en su versión más potente puede llegar hasta los 256 núcleos de GPU en total, pensad que el chip H100 de NVIDIA se queda en los 144. Sin embargo, si nos hemos de fiar por la información filtrada por Kopite en uno de sus tweets no parece que vayamos a ver un incremento importante en el número de unidades de NVIDIA Blackwell en chiplets.
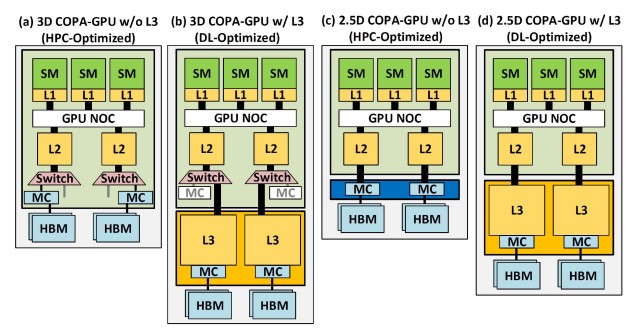
Para quien esto escribe tiene mucho sentido que NVIDIA adopte uno de los diseños presentados en el documento COPA (Composable On-Packate Architecture) que precisamente habla de las posibles configuraciones para Deep Learning y HPC para futuros diseños de la compañía.
A todo esto hemos de tener en cuenta que la SRAM ya no escala al mismo nivel que antes a partir de los 3 nm, por lo que si queremos añadir un gran bloque de caché L3 al diseño final, entonces sale más a cuenta colocar está en un chip aparte. ¿Las consecuencias de ello? Tenemos menos área dedicada a lo que es la parte de la GPU montada en el interposer.
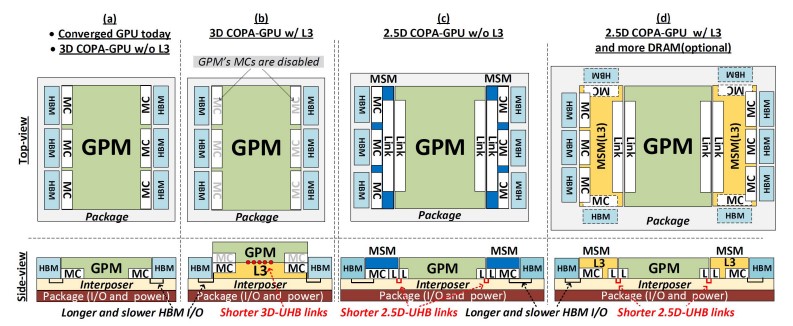
No olvidemos que desde el momento en que se está viviendo un boom en el Deep Learning y esta es la aplicación principal con la que NVIDIA está vendiendo sus chips H100 en la actualidad, pues el diseño con caché L3 agregada es el que tiene más sentido y el que mejor explicaría un salto mucho menor.
En todo caso, es posible que dicha memoria termine en el Interposer, permitiendo un diseño de 2+1 como el que hemos visto en el MI300 al no necesitar un chip adicional como caché L3. Se trataría de un diseño que la propia empresa de Jensen Huang ya había puesto encima de la mesa y que podría ser el que utilizaría NVIDIA Blackwell en chiplet. En dicho caso podría tener una mayor cantidad de núcleos, pero habría que ver que no se vieran limitados por ancho de banda.
No es el mismo chip de las RTX 50

Dado que en ese caso será la familia GB20X, lo que nos indica que su lanzamiento será mucho más tarde. En concreto sabremos que saldrá en 2025, mientras que NVIDIA Blackwell en chiplets podría salir justo en 2024. Es decir, un año antes. Por lo que no estaríamos hablando del diseño de GPU que se fabricaría en Intel. Sin embargo, todavía no hemos de descartar a TSMC de la ecuación, pero hemos de partir del hecho que las arquitecturas gaming o RTX de la compañía difieren de las HPC al añadir elementos y centrarse en el Ray Tracing.
Por otro lado, no se espera el uso de memoria HBM, por lo que en dichos diseños en principio no sería imprescindible el uso de un interposer. A todo ello, hemos de añadirle que las necesidades en lo que es la escala de computación se refiere no tienen el mismo grado de exigencia que el mercado de servidores donde se apuntará NVIDIA Blackwell.



[…] gráficas con GPU NVIDIA Blackwell para PC, el cual no es el mismo que el que veremos en servidores, GB100, y se basará en los chips GB20x, empezando por el GB202 que será el tope de gama y reemplazará […]