Todos los secretos de XDNA, el arma secreta de AMD para la IA

El futuro de AMD para por XDNA, tanto en CPU como en GPU. Y es que si bien la tarjeta gráfica más potente en la actualidad es la AMD es la RX 7900 XT, ciertas carencias la colocan por detrás de NVIDIA en algunos apartados, uno de ellos es la IA, un mercado en el que se encuentran por detrás de la marca verde al no tener una respuesta en forma de tarjeta gráfica que sea competente en dicho campo.
Índice de contenidos
Índice de contenidos
AMD en IA no seguirá los pasos de Intel y NVIDIA
Lo primero que hemos de tener en cuenta, es que mientras la estrategia de NVIDIA e Intel ha sido la creación de una nueva de ejecución encargada de ejecutar las instrucciones aritméticas con y entre matrices, el caso de AMD es diferente. Por un lado, tenemos los Tensor Cores, AMX y XMX, pero por el otro lado, tenemos las unidades AIE que han obtenido tras la compra de Xilinx por parte de la empresa de Lisa Su, uno de los elementos más importantes del porfolio que han obtenido tras la adquisición.
Dicha diferencia es crucial para entender un hecho, no vamos a ver en las arquitecturas RDNA del futuro ningún tipo de array sistólico en forma de unidad de ejecución, lo máximo que vamos a ver es el soporte de instrucciones WMMA como ya se ha visto en RDNA 3, pero el objetivo principal será siempre darle importancia a XDNA. Es decir, para cargas de Machine Learning y Deep Learning en AMD apuestan por un procesador de dominio específico aparte.
XDNA (AIE-ML) versus RDNA (GPU)

Si bien las GPU en su organización son capaces de ejecutar sin problemas algoritmos de IA, realmente el gran problema que tienen es el hecho de que no se requieren todos los elementos de la misma para poder ejecutar dichas aplicaciones, sin embargo, la organización de XDNA, basado en los AIE-ML de Xilinx nos puede ayudar a hacernos una idea.
Núcleo versus núcleo
Lo primero que hemos de ver es el núcleo, desde el sentido literal de la palabra, un núcleo es la unidad mínima que puede ejecutar una instrucción al completo, y, por tanto, puede captar, decodificar y ejecutar instrucciones, independientemente de si hablamos de un chip de propósito general como una CPU u otro para tareas concretas.
RDNA (Compute Unit)
- Unidades SIMD/Vectoriales
- Caché de instrucciones.
- Unidades de filtrado de texturas
- Caché de datos.
- Unidades de función específica.
- Memoria local.
- Ray Accelerator Unit.
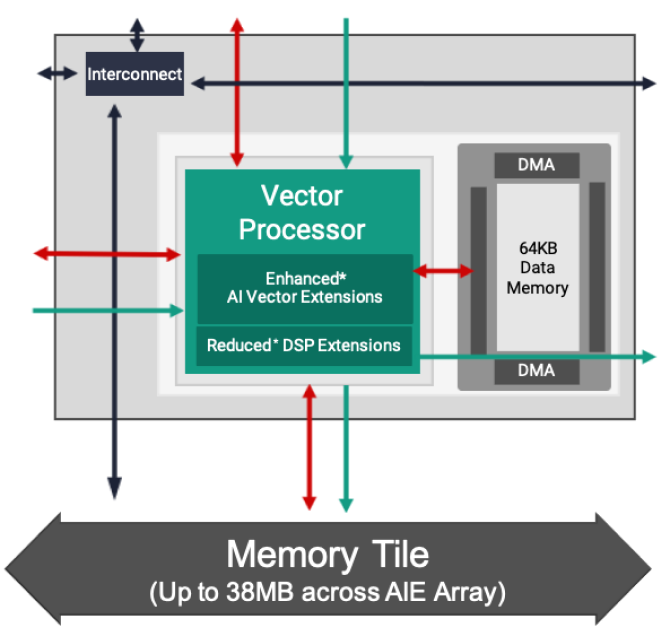
XDNA (AIE-ML)
- Unidades SIMD/Vectoriales
- Memoria Local
Para crear un procesador para la IA no necesitamos todo lo que tiene el núcleo de una GPU, pero la clave se encuentra en que no hay un sistema de caches, por lo que no se gastan transistores en ello. A cambio se utiliza una memoria local, que también se encuentra en las GPU. Dicho pozo de memoria se encuentra dentro del núcleo, a la misma latencia que la caché L1, por lo que no tiene sentido acceder a ella a través de las cachés, es más, se encuentra fuera del direccionamiento a la RAM externa y es de uso local para dicho procesador.
SIMD versus SIMD
El otro punto son las unidades SIMD o vectoriales dentro de cada núcleo, tanto en RDNA como en XDNA pueden hacer una suma y uma multiplicación en un solo ciclo de instrucción, por cada una de las ALU, sin embargo, dependiendo del tipo de dato la capacidad de computación no es la misma:
- Para instrucciones en INT16, enteros de 16 bits, el AIE-ML tiene una unidad SIMD de 64 elementos.
- En cambio, en RDNA tenemos dos unidades SIMD de 32 bits para enteros y coma flotante de 32 elementos cada una.
- A través del SIMD sobre registro para FP16, INT16 y BFLOAT16 la capacidad de cálculo se duplican.
- Si hablamos de FP16 o BFLOAT16, entonces AIE-ML dispone de una unidad SIMD de 128 elementos. Lo que se traduce en que tiene el doble de ALU para dichas instrucciones.
El motivo por el cual AIE-ML no usa precisiones de 32 bits es debido a que en la gran mayoría de aplicaciones de Deep Learning y Machine Learning a nivel doméstico no son necesarias Lo cual es una forma de ahorrar espacio en el chip.
Comunicación entre núcleos en XDNA
Aquí es donde empiezan las diferencias, en el caso de XDNA estamos ante un array sistólico, por lo que cada uno sus núcleos enviará datos en ambas direcciones a sus colindantes, a no ser que estos sean final de fila o de columna. Y es que todos los elementos están puestos en matriz, tal y como se ve en la imagen de arriba.
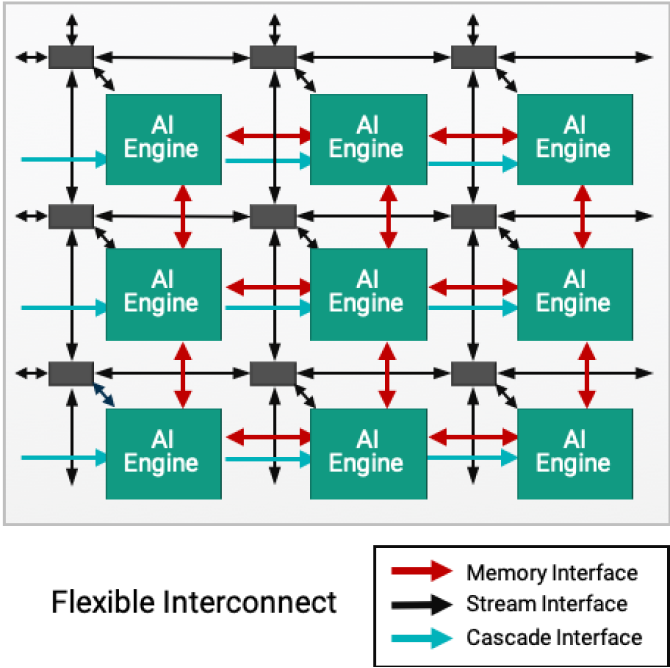
Ahora bien existen dos tipos de comunicación, una horizontal y la otra en vertical. Dependiendo de la configuración al final de las mismas puede haber lo que AMD llama un Memory Tile o no haberlo. Dicho elemento es una memoria compartida dentro del chip de 512 KB que sirve como un segundo pozo de RAM local, pero de donde los diferentes núcleos de cada cascada en vertical sacan el contenido que van a copiar en su memoria. Desde el momento en que cada núcleo de los AIE-ML tiene 64 KB de memoria local, se deduce que puede haber una columna de hasta 8 núcleos.
Luego está la configuración en horizontal, la gran diferencia es que al final de esta no hay un Memory Tile, pero las unidades pueden comunicarse con la memoria local de sus aledaños de forma directa. Una función que no existe en cascada. Tanto para la comunicación vertical como horizontal el ancho de banda entre núcleos AIE-ML o XDNA es el mismo.
Colocación en un SoC
A día de hoy tanto las CPU como las GPU de cualquier marca son un SoC, ya que tenemos varios núcleos distintos en un mismo chip, compartiendo una interfaz central común para la comunicación y un acceso compartido a la RAM. Por otro lado, Xilinx cuando era independiente de AMD ya había colocado los AIE-ML dentro de un chip de este tipo, por lo que la transición, a los Ryzen 7040 para portátiles primero y posteriormente a futuros chips de AMD es algo que debemos dar por hecho.

El 2024 se convertirá en el año en que AMD desplegará varias CPU en su gama Ryzen con unidades XDNA. Sin embargo, el punto fuerte creemos que estará en las tarjetas gráficas, mercado con el que competirá, y no solo con CDNA, con variantes de RDNA optimizados para la IA, pero no de la forma en que mucha gente se cree, sino integrando núcleos XDNA a la ecuación,
Chiplets XDNA en GPU
Sin embargo, es muy probable que veamos una renovación de sus tarjetas gráficas, pero no en forma de una nueva arquitectura RDNA 4, sino más bien un cambio «menor» para hacer que la capacidad de cara a procesar algoritmos dedicados a la IA sea más eficiente
Claro está, que dependerá de las limitaciones en espacio y consumo de cada uno de los diseños. Sin embargo, los planes de AMD respecto a XDNA se pueden ver sin problemas en una de sus patentes titulada CHIPLET-INTEGRATED MACHINE LEARNING ACCELERATORS donde se habla de un elemento bastante interesante que no es otro que un pequeño chip dedicado al Machine Learning y al Deep Learning, pero con la particularidad de que también tiene la capacidad de funcionar como controlador e interfaz con la memoria externa.

En el diagrama podemos ver lo que se llama un APD Core rodeado de cuatro (pueden ser cualquier número) Cache/ML Accelerator Chiplet. ¿A qué nos recuerda esto? Pues a la misma configuración que tenemos hoy en dia en los chips de gama alta de la arquitectura RDNA 3.


Es decir, los MCD actuales de RDNA 3 en una futura iteración, ya sea RDNA 4 o una versión mejorada de RDNA 3, integraran núcleos XDNA. Y por si os queda la duda, la propia patente confirma que APD es una GPU en otro de sus diagramas.

Cómo podéis ver, todo cuadra y hemos de partir que una GPU con una configuración de este tipo tiene mucho sentido ahora que AMD ha decidido dar el salto al uso de la IA tras años ignorando esta disciplina. Sin embargo, desde aquí no creemos que esto haya sido una decisión de un día, sino un plan muy bien pensado que ahora han empezado a ejecutar.


