
Si bien no deberíamos esperar a ver a RDNA 4 hasta bien el 2025, fecha en la que se estrenarán, supuestamente, las RTX 50, no debemos dar esto por confirmado. Especialmente por el hecho que Intel tiene planes para lanzar ARC Battlemage en 2024 y AMD no puede bajar la guardia en ningún momento.
Nota: la versión que podéis leer es una actualización realizada el día 24 de enero de 2024.
Índice de contenidos
RDNA 3 fue más lenta de lo esperado
El problema de las GPU bajo RDNA 3 es que inicialmente se lanzaron a una velocidad de reloj más baja de lo esperado. En un inicio esto se asoció al uso de un diseño disgregado o por chiplets, pero una vez apareció en el mercado la RX 7600 usando un chip de una pieza con el mismo problema, entonces es cuando se vio la realidad. La curva de velocidad de reloj y consumo energético no es eficiente en la actual arquitectura gráfica de AMD, pero se hizo necesario retocar todo, pero ya no había tiempo.

Ahora bien, nos encontramos con que en la gama alta, donde casi nadie puede comprar una tarjeta gráfica por el alto precio, se ha convertido en el lugar de batalla frente a NVIDIA. ¿La decisión de AMD respecto a RDNA 4? Salirse de la gama alta y buscar espacio en la gama media donde pese a que los márgenes son más bajos se hace necesario con tal de salvaguardar a la marca Radeon. ¿El objetivo? Ir hacia donde más cuota de mercado existe, pero ofreciendo un rendimiento por euro o dólar gastado más alto que cualquier otra tarjeta gráfica.
A simple vista, el chip más potente de RDNA 4 recordaría a Navi 32 usado en las RX 7800 y RX 7700, dado que se compondría de un GCD central y cuatro MCD, pero con cambios importantes orientados a paliar el diferencial que tienen con NVIDIA en ciertas áreas como IA y Ray Tracing. Pero sobre todo con el objetivo de poder venderlas en el incipiente mundo de la IA, donde Lisa Su ha dejado muy claro que es el objetivo de AMD.
Más Infinity Cache y ¿XDNA 2?
La tecnología V-Cache llegará a las GPU, pero no de la forma que os imagináis, sino que se montará en los MCD que a su vez integrarán las unidades XDNA 2. ¿El resultado? Tendremos una configuración de 128 MB de caché L3 para la GPU, de la cual una parte se podrá configurar como memoria local para XDNA 2.

En cuanto al bus de memoria, este será de 256 bits y la VRAM GDDR6. El motivo de ello es que toda la estructura de caché de RDNA se ha construido alrededor de dicha memoria y RDNA 4 no será la excepción a ello. Y sí, la GDDR7 sale en 2024, según sus fabricantes, pero esto no significa que vaya a ser usada de inicio en los nuevos diseños.
Por otro lado, se espera que las unidades XDNA 2 tengan la suficiente potencia como para hacer que el diseño sea interesante de cara al Deep Learning y al Machine Learning. En su versión más simple, pensada para las CPU de portátil, hablamos de 50 TOPS. En GPU y de cara a la inferencia, el rendimiento debería ser mucho más alto, situándose alrededor de cientos de TFLOPS en FP16 y BFLOAT16.
Cambios en el GCD de RDNA 4
Aquí entramos en lo importante, los últimos rumores afirman que el chip más potente tendrá una potencia equivalente a la RX 7900 XT, algo que puede resultar decepcionante. No obstante, todo se entiende si tenemos en cuenta que el objetivo de AMD es alcanzar dicho rendimiento con una configuración de 64 Compute Units, 20 unidades menos y con una potencia asignada de 300 W para toda la GPU. Por lo que RDNA 4 alcanzará velocidades de reloj más altas, pero en lo que a rendimiento 3D general aparentemente no tendrá mejoras.

Sin embargo, no solo de TFLOPS vive una arquitectura gráfica, y es que por lo visto AMD ha hecho dos mejoras importantes en RDNA 4, y no, no es al añadido de núcleos XDNA 2 como complemente para sumar más potencia para las aplicaciones de inferencia, sino que va mucho más allá. Por desgracia, la cantidad de operaciones por Compute Unit y ciclo de reloj no ha aumentado, dado que las optimizaciones parece ser que han ido, por otro lado.
Nuevo FrontEnd y “conversión” de RDNA 4 en Tile Renderer
El primero de los cambios que se aplicarán a RDNA 4, será en el FrontEnd de la GPU, y es que AMD lo ha renovado por completo. El nuevo diseño funciona de la misma manera que un Tile Renderer, con la capacidad de ordenar la geometría según su posición de pantalla sin participación del programa y creación de listas de pantalla por cada tile. Todo ello hace que la nueva arquitectura sea más cercana a una GPU para móviles

Y es que si pese a que esto ya se ha aplicado varias veces en modelos para servidores, se puede casi confirmar que el procesador de comandos gráficos pasará a ser multihilo. Por lo que podrá gestionar varias listas de pantalla al mismo tiempo. Lo cual es necesario para la conversión de RDNA 4 en un Tile Renderer, con el objetivo de no depender tanto de la memoria externa para realizar ciertas operaciones.
Todo ello se verá complementado con los cambios que os hemos comentado en los MCD de RDNA 4, los cuales permiten asignar parte de dicha caché como memoria local. De tal manera que pueden mantener cada tile buffer dentro del chip sin que este se vuelque a memoria. Lo que completa la transformación de la próxima arquitectura gráfica de AMD en un renderizador por tiles.
Ray Accelerator Unit mejorada
Si bien la capacidad de poder recorrer la estructura de datos para Ray Tracing fue bien recibida en RDNA 3, dado que hacía mucha falta. El salto en cuanto a rendimiento no fue el esperado, ya que solo vimos una subida del 50% en cuanto a la cantidad de intersecciones rayo-objeto. Pues bien, en RDNA 4, el salto será mucho más alto que en la actual generación, pero desconocemos cuál será y si tendrá la misma capacidad que en las RTX 40.

El otro punto es el soporte de ejecución fuera de orden de las olas en cada Compute Unit, una característica ya disponible en RTX 40 (vía drivers) y en ARC Alchemist (vía hardware) y que en el caso de RDNA 4 llegará por primera vez a las Radeon de AMD. Esta función tenía que aparecer en RDNA 3 bajo el nombre de OREO, pero parece ser que debutará en la siguiente generación.
Mejoras en el DSBR
Actualizamos este artículo a fecha del día 24 de enero de 2024 para hablaros de la patente de AMD, titulada Hybrid render with deferred primitive batch binning.
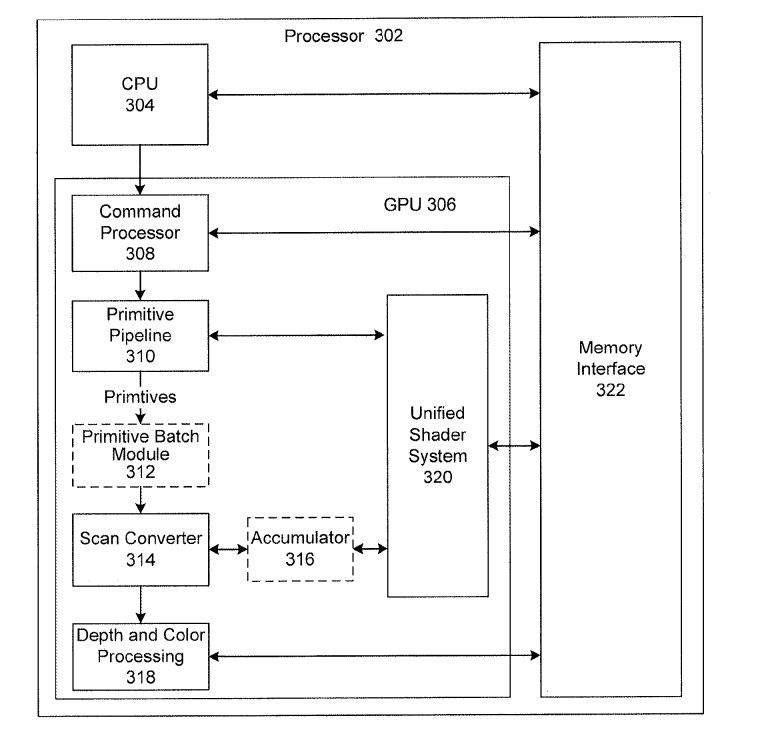
Hemos de partir del hecho de que se trata de una mejora sobre el DSBR o Draw Stream Binning Rasterizer que se vio por vez primera en las AMD Vega y que se ha implementado hasta el momento en todos los chips gráficos de AMD, y que a su vez es análogo al Tile Caching de NVIDIA.
Los cambios, hasta ahora inéditos hasta en RDNA 3 consisten en el añadido de dos unidades adicionales como son el Primitive Batch Module, el cual actuaría antes del rasterizado/scan converter y un acumulador al que podrían acceder tanto las Compute Units como la propia unidad de rasterizado.
- El Primitive Batch Module se encarga de ordenar e identificar los diferentes polígonos en los diferentes tiles que componen la escena. Al igual que en un Tile Renderer convencional, aplica el culling en cada uno de los bloques, eliminando los píxeles que quedan fuera del encuadre. Además de ello, la aplica una ID automática a cada primitiva gráfica, lo cual es clave a la hora de aplicar vectores de movimiento para el FSR.
- El acumulador se encarga de realizar la eliminación de las superficies ocultas, solo que ahora lo hace de forma más eficiente. Ahora es posible indicar de antemano si un polígono es translúcido u opaco, lo que permitirá eliminar más fácilmente la superficies totalmente ocultas. Esto se consigue estando en comunicación con las Compute Units, que envían la señal sobre el canal alfa de la textura para descartar la primitiva de la lista de fragmentos a rasterizar.
Cambios en la ISA en RDNA 4
A través de un extenso y detallado artículo llevado a cabo por Chips and Cheese, hemos podido saber detalles sobre los cambios en el set de instrucciones de RDNA 4. Si bien no lo han hecho a partir de la información completa del chip, hay que destacar que los cambios en la ISA sirven también para indicar cambios en el hardware.
- Ahora se hará posible enviar la información a niveles concretos de caché de forma directa usando 2 bits para ello. Desde la L0 dentro de la Compute Unit hasta la L3 o Infinity Cache. La ventaja de esto es que permitirá la comunicación directa entre cachés bajo un mismo nivel sin que tengan que atravesar toda la jerarquía de memoria.
- RDNA 4 seguirá soportando instrucciones WMMA como RDNA 3, pero ahora con soporte para FP8 y cálculo con matrices dispersas. En todo caso, dichas novedades se esperaban desde el momento en que las NVIDIA RTX 40 las soportan desde el primer día.
- La cantidad de instrucciones VLIW2, las cuales se procesan al doble de velocidad, aumentará en RDNA 4.
¿Qué rendimiento podemos esperar de las RX 8000 basadas en RDNA 4?
Por el momento se conoce que AMD lanzará dos chips distintos: Navi 44 y Navi 48, podéis encontrar más información sobre lo que sabemos, por el momento de ambas GPU con arquitectura RDNA 4 aquí. En todo caso, hemos de partir del hecho que estas especificaciones técnicas no vienen de la mano de la propia AMD, por lo que podrían variar en la versión final.
¡Lo último que hemos podido saber es el rendimiento en el que se sitúa cada uno de estos dos chips, y todo gracias a la cuenta de Twitter de All the Watts! Quien ya ha filtrado varias informaciones sobre futuros productos de AMD en el pasado.
- Por lo visto, Navi 48, que será el chip de gama alta en RDNA 4 estará un poco por debajo de la RX 7900 XTX en rendimiento.
- Hay que aclarar que Navi 48 tendrá un bus de 256 bits, frente a los 384 bits de Navi 31, por lo que hablamos de un chip con una menor cantidad de núcleos de GPU, pero con una velocidad de reloj mucho más grande. Dicho de otra forma, una Navi 32, pero con los suficientes GHz para casi empatar con una RX 7900 XTX.
- Navi 44, en cambio, será un chip monolítico como Navi 33, es más, todo apunta a que tendrá la misma configuración, pero una mayor velocidad de reloj. Todo ello sin tener en cuenta las mejoras en la arquitectura.
- Se dice que AMD dejaría de lado los chiplets y que ambos chips serán monolíticos.
Veremos con que nos sorprende AMD, os iremos poniendo al día.
El Tile Rendering hará que RDNA4 sea excelente en portatiles si los ensambladores no se ponen tan ortivas…
parece mucho el enfoque de intel