¿Qué configuración podemos esperar en la NVIDIA RTX 5090?

Si bien NVIDIA no ha oficializado las especificaciones de su futura RTX 5090 basada en la GPU GB202, hemos decidido hacer un ejercicio de especulación a partir de una información reciente acerca del salto en rendimiento que nos podemos esperar de una generación a otra. En todo caso, aclararos de entrada que esto es un ejercicio de pura especulación y no información oficial.
Índice de contenidos
El punto de referencia: el salto de rendimiento según la GDDR7
Hace unos días Micron mostró una diapositiva de su versión de la memoria GDDR7, que es cuanto menos interesante de ver, dado que compara el salto de rendimiento respecto a usar la nueva memoria respecto a sus antecesoras. Claro está que no debemos olvidar que serán las NVIDIA RTX 50, las primeras en usarla, por lo que en el fondo la imagen de abajo es una comparación oculta, al menos, en rendimiento, entre la actual generación de la marca verde y la siguiente, al menos preliminarmente.
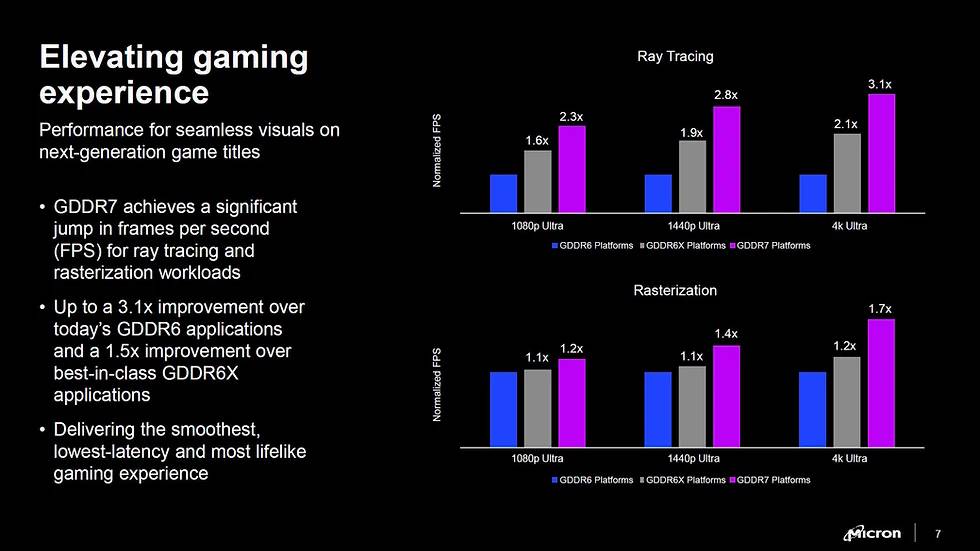
Aquí lo que nos interesa de entrada es el rendimiento a 4K Ultra en la rasterización como referente, y más bien compararlo no con la GDDR6, sino con la GDDR6X. Lo cual podemos conseguir con un sencillo cálculo:
1.7*100/1.2= 41.67%
Es decir, hemos de esperar dicho salto de rendimiento a 4K y en rasterización utilizando la GDDR7 de Micron junto a la GPU GB202 (RTX 5090) en comparación con la GDDR6X en la GPU AD102 (RTX 4090). Al menos sí tomamos en cuenta los datos de Micron, los cuales hablan de un ancho de banda de 1.5 TB/s bajo un bus de 384 bits y una memoria a 32 Gbps. Lo cual no coincide con los rumores recientes que hablan de un bus de 448 bits o incluso de 512 bits en la RTX 5090.
La importancia del ancho de banda en una GPU
Uno de los puntos cruciales a la hora de diseñar una tarjeta gráfica es el ancho de banda que tendrá, este ha de ser lo suficientemente rápido y, por tanto, venir con el suficiente caudal de datos, para que la GPU esté alimentada.

Sin embargo, el dilema se encuentra entre la velocidad por pin y la cantidad de estos.
- Una velocidad de transferencia por conexión muy alta puede crear un ahogamiento termal y provocar que el resto del sistema no alcance las velocidades de reloj esperadas. Aparte de degradar el chip mucho más rápido.
- Utilizar una mayor cantidad de pines puede suponer que para el mismo ancho de banda sea necesario una mayor cantidad de chips en el PCB y que el chip final aumente de tamaño. Lo cual es contraproducente para la velocidad de reloj.
No creemos que NVIDIA utilice una interfaz de 384 bits para la GPU GB202, el motivo principal es que los primeros chips de memoria GDDR7 no superan los 2 GB de capacidad, por lo que estaríamos hablando de una configuración de 24 GB de forma convencional y de 48 GB en modo clamshell (con dos chips compartiendo el bus de datos) y de cara a la IA esto no sería un salto en modelos como el sucesor de la RTX 6000 ADA. Un bus de 448 bits permite configuraciones de 28 GB/56 GB y el de 512 bits de 32 GB/64 GB.
Eficiencia versus realidad
La parte más costosa del rasterizado ocurre durante el texturizado, es en ese punto donde la potencia computacional necesaria para asignarle el color a cada uno de los píxeles requiere más potencia que cualquier otra etapa previa. El motivo de ello es que la cantidad de primitivas gráficas en dicha etapa del pipeline es más alta que en cualquier otro momento.

Al mismo tiempo, desde el momento en que las unidades de texturizado se encuentran en los núcleos de la GPU, dicha capacidad escala con la velocidad de reloj de estos y la cantidad de los mismos. Por lo que hemos decidido hacer una simple ecuación para saber la velocidad de reloj en las potenciales configuraciones, sería necesario para alcanzar el 41.67% de rendimiento adicional en la GPU GB202 respecto a AD102.
GPU GB202: poniendo todas las cifras encima de la mesa
No olvidemos que según Kopite7Kimi, la configuración máxima de la GPU GB202 podría ser de 12 GPC (arrays) con 8 clústeres (TPC) con 2 núcleos por Cluster (SM). Tal y como se puede ver en la imagen de abajo.

Todo ello Esto hace un total de 192 núcleos y es lo que hemos tomado como referencia. Al mismo tiempo, de las posibles configuraciones hemos descartado aquellas que son iguales o están por debajo de los 144 núcleos, que es el máximo del AD102, dado que no supondría una ventaja tener una GPU GB202 con menos núcleos que el actual tope de gama, en especial si tenemos en cuenta que se fabrican bajo la misma litografía.
| GPC (8 TPC) | GPC (6 TPC) | Núcleos activos | Núcleos desactivados | MHz |
| 12 | 0 | 192 | 0 | 2381 |
| 11 | 1 | 188 | 4 | 2431, |
| 10 | 2 | 184 | 8 | 2483 |
| 9 | 3 | 180 | 12 | 2538 |
| 8 | 4 | 176 | 16 | 2597 |
| 7 | 5 | 172 | 20 | 2657 |
| 6 | 6 | 168 | 24 | 2720 |
| 5 | 7 | 164 | 28 | 2786 |
| 4 | 8 | 160 | 32 | 2856 |
| 3 | 9 | 156 | 36 | 2929 |
| 2 | 10 | 152 | 40 | 3006 |
| 1 | 11 | 148 | 44 | 3087 |
Por otro lado, si bien la cifra de 12 GPC podría ser fija, NVIDIA puede desactivar de forma aleatoria TPC para aumentar los yields en el diseño final. Algo que lleva haciendo durante generaciones. Es por ello que primero hemos decidido buscar las posibles configuraciones de la GPU GB202 en la RTX 5090, que sea un 41.67% más potente que la RTX 4090.
De todas estas configuraciones, ¿cuál creéis que será la escogida al final por NVIDIA?


